Wait-Free Software Infrastructures
A central part of realtime interactive systems (RISs), such as collaborative virtual environments (CVEs), virtual environments (VEs) and virtual reality (VR) systems is the generation, management, and distribution of all relevant data (resp. simulation) states. In modern manifestations of these systems, usually many independent, inhomogeneous software components need to communicate and exchange data in order to simulate the given model as well as to provide data for the visual feedback. In detail, such systems usually consist of many different components such as graphics rendering, sound, several input devices, haptic rendering, physically-based simulation, model behavior, etc. All these components have to share and communicate some kind of data. For instance, the physically-based simulation gathers data from the input devices and passes its results to the graphics, haptic and sound rendering. This requires some kind of interface for the data exchange between the components. This data can be extremely large, for instance in spacecraft and spaceflight simulations, where the position of thousands of celestial bodies changes continuously by Newtons’ laws of motion. All transformations have to be passed from the simulation to the rendering component. This data exchange is usually done concurrently in highly parallel manner in order to preserve a fast simulation and immersive visual feedback to the user. Therefore, current RISs rely on some kind of data management or structure which is concurrently shared between all software components. Thus, RISs, in general, require a data and concurrency management that is easy to handle and guarantees fast access to data for both, reading and writing while maintaining a consistent simulation state even in heavily concurrent access scenarios.
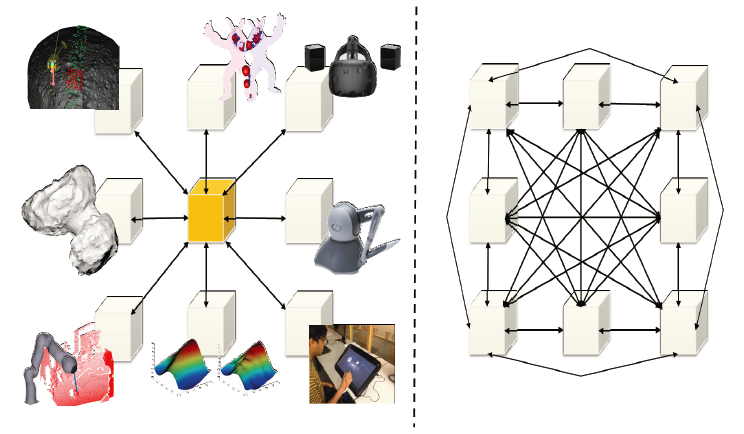
Our contribution for above research field is a novel concurrency control management (CCM) and data management that manages concurrent multithreaded access to shared data in any RIS. Our approach not only reduces the number of required interfaces from O(n^2) of standard approaches to O(n) which benefits better maintainability. Even more, it minimizes the synchronisation overhead but also guarantees simultaneous, wait-free read and write operations.
It is based on a novel wait-free hash maps data structure with no possible deadlocks or thread starvation. This data structure achieves high scalability because the wait-free concept does not introduce latencies even for massively parallel access. In addition, it provides high performance because it is completely wait-free and in-memory resident. At last, it provides high adaptability because it stores all simulation data in efficient object-oriented structures within a graph-based look-up infrastructure. In contrast to the state-of-the-art virtual testbed applications which utilize full-fledged database technology, the time-consuming serialization as well as table-based coordination and separation of relational databases are eliminated. Even more, the wait-free hash map techniques allow high performance access even for massive numbers of concurrent read and write operations. Consequently, our data management incorporates a highly responsive low-latency data access for any number of simulation components accessing it. Additionally, our approach implements the same functionality as state-of-the-art relational databases such as aggregate queries and caching strategies.
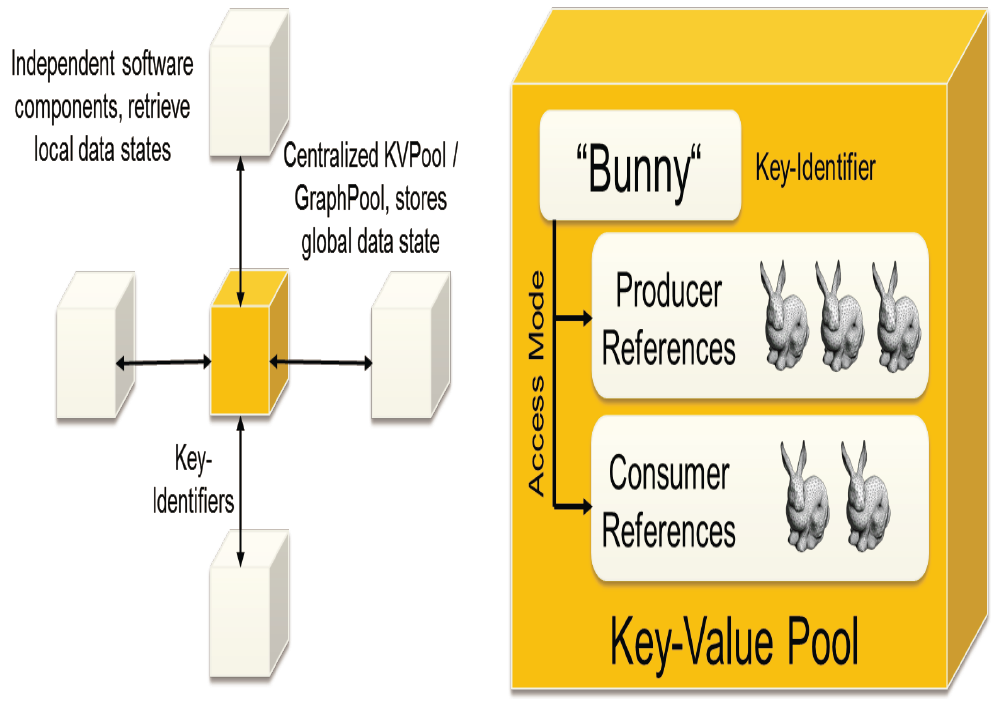
|
| In our centralized data management approach, software components communicate via unique keys (left). These keys refer to two versions of the stored data: producer and consumer version (right). |
Our approach stores static and dynamic parts of a simulation model, distributes changes caused by the simulation and logs the simulation run. Even more, our approach supports sophisticated query types of traditional relational databases. As a consequence, our approach overcomes the associated drawbacks of relational database technology for sophisticated virtual testbed applications. Additionally, our approach has several advantages compared to other state-of-the-art decentralized methods, such as persistence for simulation state over time, fast object and data identification, standardized interfaces for software components as well as a consistent world model for the overall simulation system. At last, our data structure incorporates a versioning mechanism which generates a queryable archive of the complete simulation. As a result, simulation components can be used in an online viewing mode to replay a simulation run step by step, allowing analysis and debriefing. Therefore, our approach fulfills all today's needs for data and thread management in virtual testbeds.
As introduced in the previous paragraphs, a central part of RISs is the generation, management, and distribution of the global simulation or world state. Usually many independent software components need to communicate and exchange data in these modern systems systems in order to generate this global state. These components and their corresponding performance within a RIS are governed by the functional as well as non-functional requirements of modern RIS development such as (realtime) performance, responsiveness, scalability, consistency and (re-)usability. It is very challenging to achieve these requirements within RIS development because they are usually asynchronous and use highly parallel software architectures in order to satisfy their performance requirements. Consequently, RIS development strives for reusable patterns and software architectures in order to increase the satisfaction of the above mentioned requirements, especially for massive amounts of RIS software components. In the past, the entity-component-system (ECS) approach has become a major design pattern used in modern architectures for RISs. This pattern strives for high reusability and architectural scalability. The main idea of ECS is to decouple high-level modules such as physics, rendering or sound from the low-level objects with their corresponding data. Therefore, ECS introduces three software architectural objects: entities, components and systems. These are used to describe objects of a RIS via composition instead of object-oriented inheritance.
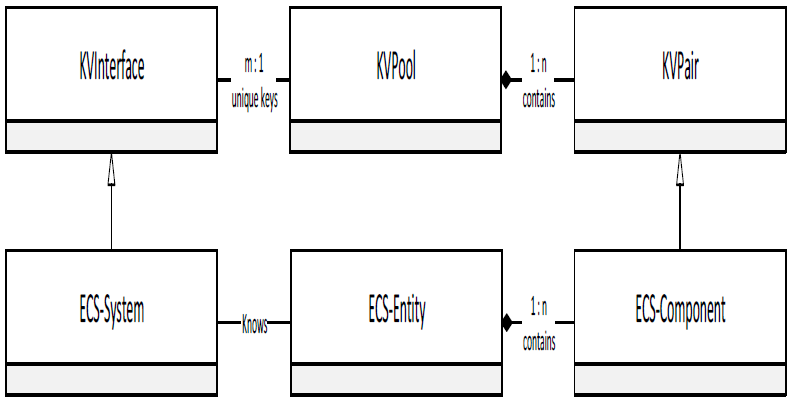
Our contribution is an extension of the ECS pattern with our high performance wait-free hash maps with efficient memory management which reduces their memory consumption. Hence, our contribution allows non-locking read and write operations of systems, leading to a highly responsive low-latency data access while maintaining a consistent state even for structured components. Simultaneously, our contribution greatly reduces the memory footprint of our wait-free hash maps by introducing novel garbage collection techniques. Our novel approach is easy to implement and fits perfectly into the implementation of wait-free hash maps without altering the ECS pattern. Our approach therefore greatly benefits the overall RIS performance when using the ECS pattern for improved maintainability and re-usability. Even more, our approach is combined with the concept of model-driven engineering (MDE), namely domain specific languages (DSMLs).
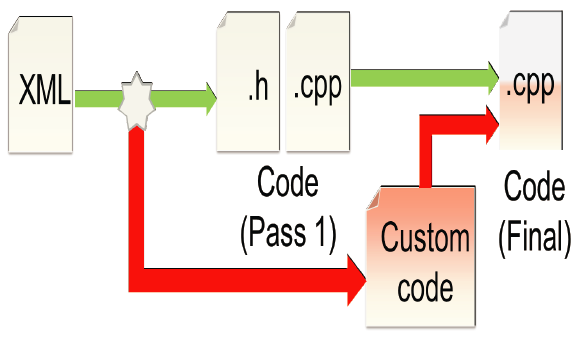
|
| Our TBCG approach: templates with all read and write operations are generated and the interface behavior is added manually. |
We developed a DSML that is able to define platform-independent models for arbitary virtual testbed applications from which, via code generation, various platform-specific models can be generated. Our approach allows easy and quick modelling of our ECS pattern based wait-free hash map software infrastructure for virtual testbeds. This leads to efficient definition, implementation via code generation, and model checking of virtual testbeds.
|
| Overview of our proposed approach. From a lightweight DSML, arbitrary domain-unrelated PIMs are defined which are used to generate the corresponding virtual testbed (PSM) with our proposed SBO methodologies. |
Results
|
|
| Timings for a read and write access. In both scenarios, our KVPool outperforms the state-of-the-art significantly for an increasing number of software components. |

|
| Performance comparison of core and aggregate queries of the GraphPool and (in-memory) relational databases. Our approach outperforms the state-of-the-art for single-component (left) and multi-component (right) scenarios. |
Publications
- Intelligent Realtime 3D Simulations, ACM SIGSIM PADS 2016, Banff, May 15 - 18, 2017
- GraphPool: A High Performance Data Management for 3D Simulations, ACM SIGSIM PADS 2016, Banff, May 15 - 18, 2017
- Wait-Free Hash Maps in the Entity-Component-System Pattern for Realtime Interactive Systems, IEEE VR: 9th Workshop on Software Engineering and Architectures for Realtime Interactive Systems SEARIS 2016, Greenville, SC, USA, March 19 - 23, 2016
- Scalable Concurrency Control for Massively Collaborative Virtual Environments, ACM Multimedia Systems - Massively Multiuser Virtual Environments, Portland, United States, March 18 - 20, 2015
- Virtual Reality for Simulating Autonomous Deep-Space Navigation and Mining, 24th International Conference on Artificial Reality and Telexistence (ICAT-EGVE 2014), Bremen, Germany, December 8 - 10, 2014
- A Framework for Wait-Free Data Exchange in Massively Threaded VR Systems, International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision (WSCG)), Plzen, Czech Republic, June 2 - 5, 2014.