

Unix Shells - Allgemeines |
| Geschichte der Shells |
|
1979 lieferte AT&T UNIX Version 7 mit der nach ihrem Erfinder Stephen Bourne benannten Shell bsh aus, die als erste Standard-Shell für Unix-Systeme gilt. Bsh basierte auf der Programmiersprache Algol 68 und sollte die Aufgaben eines Administrators automatisieren. Neue Errungenschaften der Bsh waren vor allem die History, Aliasing und die Fähigkeit der Prozesskontrolle.
So wie die verschiedenen Unix-Derivate aus dem Boden schossen, entstanden auch eine Vielzahl von Kommandozeileninterpretern mit zum einen unterschiedlichen Merkmalen und zum anderen unterschiedlichem Erfolg. Parallel zur Bsh wurde in Berkeley von Bill Joy die C-Shell - der Name lässt die nahe Verwandtschaft zur Programmiersprache C schon erahnen - entwickelt, die bald zum Lieferumfang eines jeden BSD-Unix avancierte. Gerade die Mächtigkeit der Programmierung verhalf dieser Shell zu einer großen Verbreitung. Unter Linux kommt heute oft die erweiterte Tenex-C-Shell (tcsh) zum Einsatz.
Vielleicht war ja der umstrittene Disput zwischen Bsh- und Csh-Verfechtern der Anlass
für David Korn, 1986 mit System V Release 4 (AT&T) seine Version einer Shell
auszuliefern. Die Ksh beinhaltet alle Fähigkeiten der Bsh, ergänzt um
einige Möglichkeiten der Csh.
Die Korn Shell war so ziemlich die erste Shell, die auch für andere Betriebssysteme
verfügbar wurde. Heute sind auch Bash - die um die wichtigsten Konstrukte der
Csh und Ksh erweiterte Bsh - und Tcsh unter anderen Systemen (auch Windows)
vorhanden.
| Aufgaben einer Shell |
|
Die wichtigste Aufgabe einer Shell im interaktiven Modus ist die Interpretation der Kommandozeile. Eine Shell nimmt die Eingabe des Nutzers entgegen, teilt diese an den Whitespaces (Leerzeichen, Tabulator, Zeilenumbruch) in so genannte Token auf, ersetzt Aliasse und Funktionen, organisiert die Umleitung von Ein- und Ausgaben, substituiert Variablen und Kommandos und nutzt vorhandene Metazeichen zur Dateinamensgenerierung. Anschließend sucht die Shell nach dem angegebenen Kommando und übergibt diesem die komplette Kommandozeile als Argumente.
Während der Initialisierung ist die Shell für die Umgebung des Nutzers verantwortlich. Dazu liest eine Shell spezielle, ihr zugeordnete Konfigurationsdateien ein und setzt z.B. Aliasse oder die PATH-Variable des Nutzers usw.
Ebenso bietet jede Shell die Möglichkeit der Shellprogrammierung, um bestimmte Abläufe automatisieren zu helfen. Mächtige Shells beinhalten hierzu Programmkonstrukte wie bedingte Ausführung, Schleifen, Variablenzuweisung und Funktionen.
| Parsen der Kommandozeile |
|
Das Prinzip des Parsens der Kommandozeile ist allen in diesem Kapitel besprochenen Shells gleich. Auf die konkreten Realisierungen kommen wir in den Abschnitten der speziellen Shells zurück.
| Arten von Kommandos |
|
Es existieren 4 Arten von Kommandos:
Die Nummerierung entspricht dabei der Reihenfolge, nach der eine Shell nach einem Kommando sucht.
Ein Alias ist einfach nur ein anderer Name für ein Kommando oder eine Kommandofolge. Würden wir einen Alias mit dem Namen eines vorhandenen Kommandos definieren, so wäre das originale Kommando nur noch durch Angabe seines vollständigen Zugriffspfades erreichbar:
| user@sonne> alias ls="echo 'ls ist weg'" user@sonne> ls ls ist weg user@sonne> /bin/ls ToDo entwicklung.htm khist.htm shallg.htm~ access.htm user@sonne> unalias ls |
Da ein Alias wiederum einen Alias beinhalten kann, wiederholen die Shells die Substitution solange, bis der letzte Alias aufgelöst ist.
Funktionen gruppieren Kommandos als eine separate Routine.
Builtins sind Kommandos, die direkt in der Shell implementiert sind. Einige dieser Kommandos müssen zwingend Bestandteil der Shell sein, da sie z.B. globale Variablen manipulieren (cd setzt u.a. PWD und OLDPWD). Andere Kommandos werden aus Effizienzgründen innerhalb der Shell realisiert (ls).
Ausführbare Programme liegen irgendwo auf der Festplatte. Zum Start eines Programms erzeugt die Shell einen neuen Prozess, alle anderen Kommandos werden innerhalb des Prozesses der Shell selbst ausgeführt.
| Shell und Prozesse |
|
Wer die ersten Kapitel nicht gerade übersprungen hat, dem sollte der Begriff des Prozesses schon geläufig sein. Hier noch einmal eine Zusammenfassung der Charakteristiken eines Prozesses:
Ein Prozess ist ein Programm, das sich in Ausführung befindet, d.h.
Geben wir nun auf der Kommandozeile etwas ein, ist es Aufgabe der Shell, das Kommando zu finden und, insofern es sich nicht um ein builtin-Kommando handelt, einen neuen Prozess zu erzeugen, welcher dann das Programm ausführt.
Die Shell bedient sich dabei verschiedener Systemrufe, d.h. Aufrufe von Funktionen des Kernels. Die uns nachfolgend interessierenden Systemrufe sind:

Abbildung 1: fork() - Erzeugen eines neuen Prozesses
Unter Unix ist fork() die einzige Möglichkeit, einen neuen Prozess zu
erzeugen (Threads - so genannte Leichtgewichtsprozesse - haben nicht viel mit dem
klassischen Prozesskonzept gemeinsam; für sie existieren eigene Systemrufe).
Ein existierender Prozess erzeugt also einen neuen Kindprozess, der sich
zunächst nur durch eine eigene Prozessnummer von seinem Elternprozess
unterscheidet. Der Kindprozess erhält eine exakte Kopie der Umgebung seines
Vorfahrens, einschließlich geöffneter Dateideskriptoren, Rechten (UID, GID),
Arbeitsverzeichnis, Signalen...
Beide Prozesse führen zunächst ein und dasselbe Programm aus und teilen sich vorerst diesen Speicherbereich. Erst wenn der Kindprozess ein neues Programm laden sollte, wird ihm ein eigenes Codesegment zugestanden.
Beispiel:
| /* Programm forktest.c demonstriert das Erzeugen
eines neuen Prozesses und den konkurrierenden Ablauf von Kind- und Elternprozess */ #include <stdio.h> #include <unistd.h> int main () { int pid; int counter = 8; printf("...Programm gestartet...\n"); pid = fork (); while ( --counter ) { printf("%d ", getpid()); sleep(1); /* 1 Sekunde schlafen */ fflush(stdout); /* Standardausgabe leeren */ } printf(" Ende\n"); return 0; } |
Wir übersetzen das Programm und starten es:
| user@sonne> gcc forktest.c -o
forktest user@sonne> ./forktest ...Programm gestartet... 681 680 681 680 681 680 681 680 681 680 681 680 681 Ende 680 Ende |
Erläuterung: Anhand der Ausgabe ist zu erkennen, dass der Kindprozess tatsächlich den ersten Befehl nach dem "fork()"-Aufruf ausführt, d.h. auch der Programmzeiger wurde vererbt. In der nachfolgenden Schleife gibt jeder Prozess seine PID aus. Die Aufrufe von "sleep()" und "fflush()" dienen nur der Demonstration, ohne diese würde vermutlich jeder Prozess innerhalb eines CPU-Zyklus sein Programm abarbeiten können und die Ausgaben wären nicht alternierend.
Insofern der Elternprozess nicht explizit auf die Beendigung seiner Kinder wartet (siehe "wait") , laufen die Prozesse parallel ab.
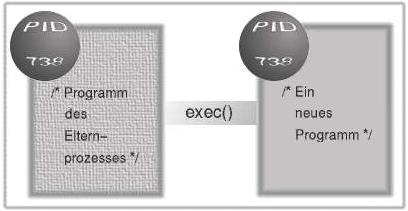
Abbildung 2: exec() - Laden eines neuen Programms
Das Starten von Prozessen, die alle ein und dasselbe Programm ausführen, ist auf
die Dauer nicht sehr produktiv...
Zum Glück liefert der Aufruf von fork() einen Wert zurück, anhand dessen die
beteiligten Prozesse erfahren können, wer denn nun das Kind und wer der Vorfahre
ist. fork() gibt, falls kein Fehler auftrat, beim Elternprozess die PID des Kindes
zurück (bei Fehler "-1"). Im Kindprozess bewirkt der Systemruf die Rückgabe des
Wertes "0".
Anhand des Rückgabewertes wird ein Programm nun alternative Programmpfade
beschreiten. Der Kindprozess wird mittels exec() (es existieren verschiedene
Systemrufe zu diesem Zweck) ein neues Programm nachladen. Ab diesem Zeitpunkt wird
für das Programm des Kindes ein eigener Speicherbereich reserviert.
| user@sonne> bash user@sonne> ps -T PID TTY STAT TIME COMMAND 9905 tty4 S 0:00 login -- user 9977 tty4 S 0:00 -sh 9986 tty4 S 0:00 bash 9994 tty4 R 0:00 ps -T user@sonne> exec ps -T PID TTY STAT TIME COMMAND 9905 tty4 S 0:00 login -- user 9977 tty4 S 0:00 -sh 9986 tty4 R 0:00 ps -T user@sonne> ps -T PID TTY STAT TIME COMMAND 9905 tty4 S 0:00 login -- user 9977 tty4 S 0:00 -sh 10018 tty4 R 0:00 ps -T |
Beispiel: In einem C-Programm wird ein "exec()"-Aufruf wie folgt vollzogen:
| /* Programm exectest.c demonstriert das Laden
eines neuen Programms durch den Kindprozess */ #include <stdio.h> #include <unistd.h> int main () { int pid; printf("...Programm gestartet...\n"); pid = fork (); if ( pid ) { printf("[Eltern (%d)] PID des Kindes: %d\n", getpid(), pid); } else { printf("[Kind (%d)] PID des Elternprozesses: %d\n", getpid(), getppid()); execl("/bin/date", "-u", NULL); } printf("[%d ]Programmende\n", getpid()); return 0; } |
Wiederum übersetzen wir das Programm und starten es:
| user@sonne> gcc exectest.c -o
exectest user@sonne> ./exectest ...Programm gestartet... [Eltern (3311)] PID des Kindes: 3312 [Kind (3312)] PID des Elternprozesses: 3311 Sam Jul 8 09:05:07 MEST 2000 [3311] Programmende |
Erläuterung: Das Programm demonstriert das Beschreiten alternativer Programmpfade. Für den Elternprozess ist "pid" verschieden von "0", so wird der erste Teil des "if"-Konstrukts betreten. Im Falle des Kindprozesses liefert "pid" "0", so dass mit dem "else"-Zweig fortgefahren wird. Nach einer Ausgabe wird das Kind das aktuelle Programm durch das Programm "date" ersetzen. Der Systemruf "exec()" existiert nicht selbst als C-Funktion, sondern ist in verschiedenen Varianten implementiert, eine davon ist "execl()". Der Kindprozess hat nun nichts mehr mit dem alten Programm zu tun, deshalb erscheint von ihm auch keine "Programmende"-Ausgabe.
Ein Prozess beendet seine Existenz spätestens, wenn das ausgeführte Programm abgearbeitet ist. Innerhalb eines Programms kann dieses an beliebiger Stelle mit dem Systemruf exit() verlassen werden. Ein Prozess sendet vor seinem Ende noch ein Signal "SIGCHILD" an seinen Elternprozess und wartet, dass dieser das Signal behandelt. Gleichzeitig sollte jedes Programm einen Rückgabewert ("Status") liefern, der den Erfolg (Wert "0") oder einen möglichen Fehlercode (Wert "1-255") meldet.
Der Status des letzten Kommandos kann in einer Shell abgefragt werden:
| # bash, ksh, tcsh user@sonne> echo $? 0 # (t)csh user@sonne> echo $status 0 |
Eine Shell wird, während ein Kindprozess seine Arbeit erledigt, auf dessen Rückkehr warten. Dazu ruft die Shell (und die meisten Programme, die weitere Prozesse erzeugen, verfahren so) den Systemruf wait() auf und geht in den schlafenden Zustand, aus dem sie erst erwacht, wenn der Kindprozess terminiert.
| user@sonne> sleep 10 & wait
%1 # 10 Sekunden verstreichen... user@sonne> |
Hat der Elternprozess das Signal des Kindes behandelt, gilt dieser Prozess als beendet, d.h. sein gesamter Speicherbereich wurde freigegeben und sein Eintrag aus der Prozesstabelle des Kernels entfernt.
Beispiel:
| /* Programm waittest.c demonstriert das explizite Warten des Elternprozesses auf das Ende des Kindes */ #include <stdio.h> #include <unistd.h> int main () { int pid; int counter = 8; printf("...Programm gestartet...\n"); pid = fork (); if ( pid ) { printf("[Eltern (%d)] PID des Kindes: %d\n", getpid(), pid); wait(pid); } else { printf("[Kind (%d)] PID des Elternprozesses: %d\n", getpid(), getppid()); } while ( --counter ) { printf("%d ", getpid()); sleep(1); /* 1 Sekunde schlafen */ fflush(stdout); /* Standardausgabe leeren */ } printf(" Ende\n"); return 0; } |
Wir übersetzen das Programm und starten es:
| user@sonne> gcc waittest.c -o
waittest user@sonne> ./waittest ...Programm gestartet... [Eltern (3341)] PID des Kindes: 3342 [Kind (3342)] PID des Elternprozesses: 3341 3342 3342 3342 3342 3342 3342 3342 Ende 3341 3341 3341 3341 3341 3341 3341 Ende |
Erläuterung: Nach der ersten Ausgabe durch den Elternprozess wartet dieser mittels "wait()", bis sein Kindprozess seine Arbeit beendet hat. Deshalb erscheinen die Ausgaben der PID des Elternprozesses erst nach denen des Kindes.
Ein Elternprozess muss nicht auf die Terminierung seiner Kindprozesse warten. Sendet in diesem Fall ein Kind das Signal "SIGCHILD", dann befindet es sich aus Sicht des Systems im Zustand Zombie. Der Prozess ist zwar beendet, aber sein Signal wurde noch nicht behandelt und der Eintrag in der Prozesstabelle existiert weiterhin.
Es soll auch vorkommen, dass die Eltern das Zeitliche vor ihren Nachfahren segnen (z.B. durch expliziten Abbruch durch den Nutzer oder durch einen Programmfehler). In einem solchen Fall spricht man vom Kind von einem Waisen. In dieser Situation übernimmt init - der Vorfahre aller Prozesse - die Rolle des Elternprozesses.
| Prozesskommunikation |
|
Es gibt eine Reihe von Möglichkeiten, wie Prozesse untereinander Nachrichten austauschen können. Gebräuchliche Mechanismen unter Unix-Systemen sind die Interprozesskommunikationen "IPC" nach SystemV und einige BSD-Entwicklungen. Dazu zählen:
Von den erwähnten Mechanismen stellen die Shells zur Kommunikation der in ihnen gestarteten Prozesse Pipes (benannt/unbenannt) und Signale zur Verfügung.
Eine Pipe verbindet die Ausgabe eines Kommandos mit der Eingabe eines anderen Kommando. D.h. das erste Kommando schreibt seine Ausgaben anstatt auf die Standardausgabe in die Pipe, während das zweite Kommando aus dieser Pipe und nicht von der Standardeingabe liest. Beliebig viele Kommandos lassen sich durch Pipes miteinander verknüpfen. Die Shell kümmert sich dabei um die Synchronisation, so dass ein aus der Pipe lesendes Kommando tatsächlich erst zum Zuge kommt, nachdem ein schreibendes Kommando den Puffer der Pipe gefüllt hat.
Nicht alle Kommandos akzeptieren ihre Eingaben aus einer Pipe. Kommandos, die es tun, bezeichnet man deshalb auch als Filter.
Alle uns interessierenden Shells stellen als Symbol für die Pipe den Strich "|" zur Verfügung:
| user@sonne> ls -l | cut -b 0-12,56- | less |
Eine durch das Zeichen "|" realisierte Pipe bezeichnet man als unbenannte Pipe.
Die Shell bedient sich des pipe()-Systemrufes und erhält vom Betriebssystem
einen Deskriptor auf die Pipe. Gleichzeitig stellt der Kernel einen Speicherbereich
bereit, den sich die durch die Pipe verbundenen Prozesse teilen. Sind alle Pipes der
Kommandozeile erzeugt, startet die Shell für jedes Kommando einen Kindprozess und
setzt deren Dateideskriptoren auf die entsprechenden Pipedeskriptoren.
Eine Kommunikation über einen solchen Pufferbereich im Kernel geht immer schneller,
als die Kommunikation über eine Fifo-Datei (First In First Out). Fifo-Dateien
implementieren die benannten Pipes (named pipes). Das Anlegen einer Fifo-Datei
erfolgt mit:
| user@sonne> mkfifo fifo_datei user@sonne> ls -l fifo_datei prw-r--r-- 1 user users 0 Jun 2 11:00 fifo_datei |
Mit den Mechanismen der Ein- und Ausgabeumleitung kann ein Prozess in eine solche Datei schreiben, während ein anderer aus ihr liest. Mittels "Named Pipes" können auch Prozesse kommunizieren, die nicht unmittelbare Nachfahren der Shell sind.
Jedes Signal ist mit einer bestimmten Reaktion verbunden. Es liegt in der Verantwortung des Entwicklers, ob ein Programm auf ein Signal mit den "üblichen" Aktionen antwortet oder ob es dieses Signal sogar ignoriert. Das Signal "KILL" (Signalnummer 9) beendet einen Prozess, ohne dass dieses vom ausgeführten Programm abgefangen werden kann.
Wichtige Signale und ihre Wirkung sind (die vollständige Liste der Signale ist in der Datei "/usr/include/signal.h" zu finden):
SIGHUP (1)
Terminal-Hangup, bei Dämonen verwendet, um ein erneutes Einlesen der Konfigurationsdateien zu erzwingen
SIGINT (2)
Tastatur-Interrupt
SIGQUIT (3)
Ende von der Tastatur
SIGILL(4)
Illegaler Befehl
SIGAbrT (5)
Abbruch-Signal von abort(3)
SIGFPE (8)
Fließkommafehler (z.B. Division durch Null)
SIGKILL (9)
Unbedingte Beendigung eines Prozesses
SIGSEGV (11)
Speicherzugrifffehler
SIGPIPE (13)
Schreiben in eine Pipe, ohne dass ein Prozess daraus liest
SIGTERM (15)
Prozess soll sich beenden (default von kill)
SIGCHLD (17)
Ende eines Kindprozesses
SIGCONT (18)
Gestoppter Prozess wird fortgesetzt
SIGSTOP (19)
Der Prozess wird gestoppt
SIGTSTP (20)
Ausgabe wurde angehalten
SIGUSR1 (30)
Nutzerdefiniertes Signal
Die Shells beinhalten das Kommando kill, um Signale "von außen" an Prozesse versenden zu können. Der Aufruf lautet:
| kill <Signalnummer> <Prozessnummer[n]> |
Die "Signalnummer" kann dabei als numerischer Wert oder durch den symbolischen Namen ("TERM", "HUP, "KILL", ...) angegeben werden.
|
user@sonne> kill -HUP 'cat /var/run/inetd.pid' user@sonne> kill -15 2057 2059 |
Das Versenden einiger Signale unterstützen die Shells durch Tastenkombinationen. Während die Csh nur das [Ctrl]-[C] akzeptiert, existieren unter der Bsh, Ksh und Tcsh mindestens folgende Shortcuts:
[Ctrl]+[C]
SIGINT - Ausführung des aktiven Prozesses abbrechen
[Ctrl]+[Z]
SIGSTOP, stoppt die Ausführung des aktiven Prozesses
| Umgebung und Vererbung |
|
Nach einem erfolgreichen Anmelden ins System steht dem Nutzer i.d.R. eine komplette Arbeitsumgebung zur Verfügung. Unter anderem sind wichtige Shellvariablen (PATH, USER, DISPLAY, ...) vorbelegt, einige Aliasse sind vorhanden, bestimmte Programme wurden bereits gestartet...
Für diese initiale Umgebung sind verschiedene Konfigurations-Dateien der Shells verantwortlich, die teils bei jedem Start einer Shell, teils nur beim Start einer Login-Shell abgearbeitet werden.
Die Bash und die Ksh führen während des ersten Starts die Kommandos der Datei /etc/profile aus. Ein Ausschnitt dieser, in dem einige Shellvariablen vorbelegt und Aliasse gesetzt werden, sei kurz aufgelistet:
| # Ausschnitt einer Datei /etc/profile PROFILEREAD=true umask 022 ulimit -Sc 0 # don't create core files ulimit -d unlimited MACHINE=`test -x /bin/uname && /bin/uname --machine` PATH=/usr/local/bin:/usr/bin:/usr/X11R6/bin:/bin for DIR in ~/bin/$MACHINE ~/bin ; do test -d $DIR && PATH=$DIR:$PATH done test "$UID" = 0 && PATH=/sbin:/usr/sbin:/usr/local/sbin/:$PATH export PATH if test "$UID" = 0 ; then LS_OPTIONS='-a -N --color=tty -T 0'; else LS_OPTIONS='-N --color=tty -T 0'; fi export LS_OPTIONS alias dir='ls -l' alias ll='ls -l' alias la='ls -la' alias l='ls -alF' alias ls-l='ls -l' |
Zum jetzigen Zeitpunkt sollte den Leser nur die Tatsache interessieren, dass die wichtigen Variablen beim Start einer Shell vorbelegt werden. Die Erläuterung der verwendeten Syntax bleibt den Abschnitten zur Programmierung der Shells vorbehalten.
Im Falle der Bash folgt die Abarbeitung einer Reihe weiterer Dateien, sofern diese im Heimatverzeichnis des jeweiligen Nutzers existieren. Die Dateien sind: ~/.bash_profile, ~/.bash_login und ~/.profile. Alle drei Dateien können vom Besitzer, also dem Nutzer selbst, bearbeitet werden und ermöglichen eine individuelle Einrichtung der Umgebung.
Die Ksh betrachtet neben der schon erwähnten /etc/profile nur die Datei ~/.profile.
Wird die Bash nicht als Loginshell gestartet (z.B. als Subshell zum Ausführen eines Skripts), dann bearbeitet sie nur die Datei ~/.bashrc. Die Ksh liest keine Konfigurationsdatei ein.
Die Tcsh verwendet eine grundlegend andere Programmiersprache. Demzufolge benötigt sie auch andere Konfigurationsdateien. Die Dateien /etc/csh.cshrc und /etc/csh.login übernehmen dabei die Rolle der /etc/profile von Bash und Ksh. Die Ausschnitte aus diesen, die im wesentlichen dieselben Initialisierungen veranlassen, die weiter oben im Beispiel zur /etc/profile dargestellt wurden, seien hier angeführt:
| # Ausschnitt einer Datei /etc/csh.cshrc setenv MACHTYPE `uname -m` unalias ls if ( "$uid" == "0" ) then setenv LS_OPTIONS '-a -N --color=tty -T 0'; else setenv LS_OPTIONS '-N --color=tty -T 0'; endif alias ls 'ls $LS_OPTIONS' alias la 'ls -AF --color=none' alias ll 'ls -l --color=none' alias l 'll' alias dir 'ls --format=vertical' alias vdir 'ls --format=long' alias d dir; alias v vdir; # Ausschnitt einer Datei /etc/csh.login umask 022 setenv SHELL /bin/tcsh |
Weitere Dateien, die während des Starts einer (T)csh betrachtet werden, liegen im Heimatverzeichnis und sind: ~/.tcshrc oder, falls erstere Datei nicht existiert, ~/.cshrc, ~/.history, ~/.login und ~/.cshdirs. Die Reihenfolge der Auswertung der Dateien hängt von der konkreten Implementierung ab.
Vererbung im Sinne der Prozessentstehung wurde im Punkt Shell und Prozesse besprochen. Für den Nutzer ist insbesondere der Geltungsbereich von Variablen von Bedeutung, die alle Shells verwenden, um das Verhalten der in ihnen gestarteten Programme zu steuern.
Die Shells kennen lokale und globale Variablen. Eine lokale Shellvariable ist dabei nur innerhalb der Shell ihrer Definition sichtbar und wird nicht an die in der Shell gestarteten Programme weiter gereicht. Globale Variablen hingegen sind ab der Shell ihrer Einführung sichtbar, also auch in allen aus dieser Shell gestarteten Programmen.
Zur Definition von Variablen existiert in allen Shells das builtin-Kommando set:
| user@sonne> set local_x=5 user@sonne> echo $local_x 5 user@sonne> set local_string="Enthält die Zuweisung Leerzeichen, muss sie 'gequotet' werden" user@sonne> echo $local_string Enthält die Zuweisung Leerzeichen, muss sie 'gequotet' werden |
In der Bash und Ksh kann auf das Kommando set verzichtet werden, da beide Shells anhand des Gleichheitszeichens eine Zuweisung erkennen. Allerdings dürfen im Unterschied zur (T)csh bei beiden keine Leerzeichen vor und nach dem Gleichheitszeichen stehen.
Dass eine solche Variable tatsächlich nur in der aktuellen Shell sichtbar ist, lässt sich leicht überprüfen:
| user@sonne> set local_x=5 user@sonne> bash user@sonne> echo $local_x user@sonne> exit user@sonne> echo $local_x 5 |
Im Beispiel wurde eine Subshell (die bash) gestartet, in dieser ist die Variable "local_x" nicht bekannt (leere Zeile).
Soll eine Variable nun auch in den anderen Shells sichtbar sein, muss sie exportiert werden:
| user@sonne> set local_x=5 # Bash und Ksh: user@sonne> export local_x # (T)csh user@sonne> setenv local_x |
Wir testen die Existenz der Variable in einer Subshell:
| # Beispiel anhand der Bash: user@sonne> export local_x=5 user@sonne> bash user@sonne> echo $local_x 5 user@sonne> exit user@sonne> echo $local_x 5 |
| Umleitung der Ein- und Ausgaben |
|
Alle Ein- und Ausgaben werden vom Kernel über den Mechanismus der File-Deskriptoren behandelt. So ein Deskriptor ist eine kleine nichtnegative Zahl (unsigned Integer), die einen Index auf eine vom Kernel verwaltete Tabelle ist. Jeder offene E/A-Kanal und jede offene Datei (named Pipe, Socket) wird nur über einen solchen Eintrag angesprochen.
Jeder Prozess erbt nun seine eigene Deskriptortabelle von seinem Vorfahren. Üblicherweise sind die drei ersten Einträge der Tabelle (0, 1 und 2) mit dem Terminal verbunden und werden mit Standardeingabe (0), Standardausgabe (1) und Standardfehlerausgabe (2) bezeichnet. Öffnet ein Prozess nun eine Datei (oder eine named Pipe oder einen Socket), so wird in der Tabelle nach dem nächsten freien Index gesucht. Und dieser wird der Deskriptor für die neue Datei. Die Größe der Deskriptor-Tabelle ist beschränkt, so dass nur eine bestimmte Anzahl Dateien gleichzeitig geöffnet werden können (Vergleiche Limits unter Linux).
Man spricht von E/A-Umleitung, sobald ein Dateideskriptor nicht mit einem der Standardkanäle 0, 1 oder 2 verbunden ist. Shells realisieren die Umleitung, indem zunächst der offene Deskriptor geschlossen wird und die anschließend geöffnete Datei diesen Deskriptor zugewiesen bekommt.
Standardein- und Standardausgabe lassen sich in allen drei Shells analog manipulieren:
| user@sonne> cat < infile > outfile |
Die Shells lösen solche Umleitungen von links nach rechts auf. Im Beispiel wird also zunächst der Deskriptor der Standardeingabe geschlossen (symbolisiert durch "<"), anschließend wird die Datei "infile" geöffnet. Sie erhält den ersten freien Index zugewiesen und dieser ist nun die "0". Im nächsten Schritt wird die Standardausgabe geschlossen (Symbol ">"). Die nun zu öffnende Datei "outfile" bekommt den Deskriptor "1" zugewiesen. Das Kommando "cat" bezieht also seine Eingaben aus "infile" und schreibt das Ergebnis nach "outfile".
Die Umleitung der Standardfehlerausgabe wird bei der (T)csh etwas abweichend vom Vorgehen bei Bash und Ksh gehandhabt. Der Grund ist, dass man bei Bash und Ksh das Umleitungssymbol mit einem konkreten Deskriptor assoziieren kann (z.B. bezeichnet "2>" die Standardfehlerausgabe), die (T)csh aber keine solche Bezeichnung für die Standardfehlerausgabe kennt.
Das obige Beispiel hätte man in Bash und Ksh auch folgendermaßen ausdrücken können:
| user@sonne> cat 0< infile 1> outfile |
Und analog zu diesem Schema lässt sich gezielt die Standardfehlerausgabe umleiten:
| # Nur Bash und Ksh user@sonne> find / -name "README" > outfile 2> errfile |
Die (T)csh kennt, wie auch Bash und Ksh, das Symbol >&, womit gleichzeitig Standard- und Standardfehlerausgabe in eine Datei umgeleitet werden können. Der Umweg, den man zur Umleitung der Fehler in der (T)csh beschreiten muss, geht über die Verwendung einer Subshell, in der nun die normalen Ausgaben abgefangen werden, und das, was übrig bleibt (Fehler), wird außerhalb der Subshell behandelt.
| # Tcsh user@sonne> (find / -name "README" > outfile) >& errfile |
Sie als Leser finden das verwirrend? Dann wollen wir Ihnen einen Vorgeschmack geben, welche Feinheiten der Ein- und Ausgabeumleitung die kommenden Kapitel für Sie bereit halten.
Hier einige Beispiele für die Bash und Ksh:
| # Standardausgabe dorthin senden, wo die Fehler
hingehen user@sonne> find / -name "README" 1>&2 # Datei als Deskriptor 3 zum Lesen öffnen user@sonne> exec 3< infile # "infile" sortieren und nach "outfile" schreiben user@sonne> sort <&3 > outfile # "infile" schließen user@sonne> exec 3<&- |
| Skripte |

|
Immer wieder wird man auf Probleme treffen, bei denen man sich fragt, warum es kein Programm gibt, das dieses löst? Entweder weil es zu komplex ist, ein solches zu schreiben und noch niemand solch starken Bedarf verspürte, dass er sich selbst dem Brocken widmete. Oder weil es so einfach ist, dass es sich quasi jeder selbst zusammenbasteln könnte.
Den umfangreichen Problematiken wird man nur schwerlich oder gar nicht mit Mitteln der Shellprogrammierung beikommen können, aber gerade wer reichlich auf der Kommandozeile hantiert, wird Problemstellungen begegnen, die immer und immer wiederkehren. Warum jedes Mal mühsam die Gedanken ordnen, wenn es einzig der Erinnerung eines Programmnamens bedarf, welches das Schema automatisiert?
In den nächsten Kapiteln werden Sie genügend Gelegenheit haben, der einem Neuling verwirrenden Syntax der Shellskripte Herr zu werden. Sie werden die unterschiedlichen Möglichkeiten, die die Shells bieten, bewerten und sich letztlich auf die Anwendung nur einer Shellprogrammiersprache festlegen. Welche das sein wird, ist Geschmackssache und wir hoffen mit der Reihenfolge unserer Darlegung (bash, tcsh, ksh), keine vorschnellen Wertungen beim Leser hervorzurufen. Jede der Sprachen hat Stärken und Schwächen...
Zu diesem Zeitpunkt möchten wir nur die Realisierung eines kleinen Programms mit den drei Shellsprachen gegenüber stellen, ohne irgend welche Wertungen einfließen zu lassen. Voran gestellt sei die Idee, die zum Schreiben des Skripts animierte.
Die Aufgabe. Die vorliegende Linuxfibel entsteht auf Basis von html-Dateien. Wir wirken zu dritt an der Realisierung, teils testen und schreiben wir in der Firma, teils daheim. Um die Dateien zu übertragen, sammeln wir sie in einem Archiv. Nun geschieht es immer wieder, dass ein schon "fertiger" Abschnitt oder eine Grafik doch wieder verworfen wird, so löschen wir nicht gleich die alte Datei, sondern nennen sie um und arbeiten auf einer Kopie weiter. Erzeugten wir nun ein neues Archiv, enthielt es die alten und die neuen Dateien und war damit viel größer, als eigentlich notwendig. In dem Wirrwarr von ca. 300 Dateien den Überblick zu wahren, war vergebene Müh', also kam die Idee zu einem Skript, das Folgendes realisieren sollte:
Bash und Ksh unterscheiden sich im Sinne der Programmierung nur unwesentlich, in unserem Beispiel überhaupt nicht. Um das Skript von der Korn Shell ausführen zu lassen, müssen Sie nur die erste Zeile von "#!/bin/sh" auf "#!/bin/ksh" ändern.
|
user@sonne> cat find_in_bash #!/bin/sh actual_entry=0 filelist[$actual_entry]=${1:?"Usage: $0 <filename>"} dir=$(dirname $filelist[actual_entry]) # Liste der *.htm-Dateien, die von der Startdatei aus erreichbar sind while :; do # set ""$(...) auf eine Zeile! set ""$(sed -n 's/.*[Hh][Rr][Ee][Ff]="\(.*\.htm\).*/\1/p' ${filelist[$actual_entry]} | egrep -v"http|${filelist[$actual_entry]}") for i do [ "$i" = "" ] && continue if ! echo ${filelist[@]} | fgrep -q $i; then filelist[${#filelist[*]}]="$dir/$i" fi done actual_entry=$(($actual_entry+1)) [ "$actual_entry" -ge"${#filelist[*]}" ] && break done # Bilderliste pictures=$(sed -n's/.*[Ss][Rr][Cc]="\(.*\.gif\).*/\1/p' ${filelist[*]}) pictures="$pictures $(sed -n 's/.*[Ss][Rr][Cc]="\(.*\.jpg\).*/\1/p' ${filelist[*]})" set $pictures picturelist[0]="$dir/$1" for i do if ! echo ${picturelist[@]} | fgrep -q $i; then picturelist[${#picturelist[*]}]="$dir/$i" fi done echo ${filelist[*]} ${picturelist[*]} |
Eine gänzlich andere, an die Programmiersprache C angelehnte Syntax verwendet die Tcsh. Beachten Sie bitte den Hinweis im Skript, dass bestimmte Zeilen in der Programmdatei zusammengefügt werden müssen. Die Tcsh kennt kein Zeilenfortsetzungszeichen, wie die Bash und Ksh mit dem Backslash.
| user@sonne> cat find_in_tcsh #!/bin/tcsh set actual_entry = 1 set filelist = $1 set dir = `dirname $filelist` # Liste der *.htm-Dateien, die von der Startdatei aus erreichbar sind while (1) # Eine Zeile! set files = `sed -n's/.*[Hh][Rr][Ee][Ff]="\(.*\.htm\).*/\1/p' $filelist[$actual_entry] | egrep -v "http|$filelist[$actual_entry]"` # Zeile beendet... while ( $#files ) echo $filelist | fgrep -q $files[1] if ( $status ) then set filelist=($filelist $dir/$files[1]) endif shift files end @ actual_entry += 1 echo "Vergleich $actual_entry mit $#filelist" if ( $actual_entry > $#filelist ) then break endif end # Bilderliste set picturelist="" set tmp=($filelist) while ($#tmp) # Eine Zeile! set pictures = `sed -n's/.*[Ss][Rr][Cc]="\(.*\.gif\).*/\1/p' $tmp[1]` # Zeile beendet... # Eine Zeile! set pictures = ($pictures `sed -n's/.*[Ss][Rr][Cc]="\(.*\.jpg\).*/\1/p' $tmp[1]`) # Zeile beendet... while ($#pictures) echo xxx $picturelist | fgrep -q $pictures[1] if ($status) then set picturelist = ($picturelist $dir/$pictures[1]) endif shift pictures end shift tmp end echo "$filelist $picturelist" |
Falls Sie eines der Skripte in einer Datei gespeichert haben, so müssen Sie dieses noch mit den Ausführungsrechten versehen:
| user@sonne> chmod +x find_in_bash |
Sollten Sie dieses vergessen, wird eine Shell mit der Ausschrift "command not found" Ihr Anliegen abweisen.